David Herron
Tags: Node.JS »»»»
When native Promise and async/await support was added to Node.js, the process object gained some error events to notify the program about un-handled or un-caught error conditions. It's important to handle such errors, but of course we sometimes neglect to set up error handlers for every possible error condition. The primary purpose for these event handlers is so we know about program errors that we failed to catch. Node.js provides default error handlers which leave a bit to be desired. The log-process-errors assists with these issues.

If a tree falls in the forest, but nobody was around to hear it, was there actually any sound? Yes, of course there was sound, and there were birds and other animals to hear it, but a human wasn't there to record the event. Likewise, if your Node.js program generates an error, but nothing in the program catches or otherwise handles that error, then the error notification spurts into nowhere. Because the responsible human is not notified, that human cannot correct the code, and a danger lurks inside the application.
In Node.js there are several events generated by the process object for notifying the program of errors which were not handled. Any unhandled exception, any unhandled promise rejection, or any other unhandled error, means error-handling code is missing, somewhere. To catch unhandled exceptions or unhandled promise rejections, the coder needs to know to add corresponding event handlers on the process object. Making it more complicated, unhandled errors may silently disappear into the ethers, leaving the coder in the dark about problems lurking inside their program.
The current list of events for unhandled errors are:
| Event Name | Node.js version | Discussion |
|---|---|---|
multipleResolves |
added v10.12.0 | This is emitted when a Promise has been resolved or rejected more than once. |
uncaughtException |
added v0.1.18, improved v12.0.0 | This is emitted when an Exception bubbles its way back to the main event loop. |
unhandledRejection |
added v1.4.1, improved v6.0.0 and v7.0.0 | This is emitted when a Promise was rejected, but the rejection was not caught. |
warning |
added v6.0.0 | This is emitted when Node.js detects conditions which require attention, but are not errors. |
For each of these we can consult the Node.js process package documentation, learn about the notification API, and write handler functions like this:
process.on('unhandledRejection', (reason, promise) => {
// .. handle the error
});
But, do we always remember to do this? Do we always remember to catch every error? When a new Node.js release adds a new unhandled error event, do we remember to add the handler to our program?
A solution is to use a package that installs every error handler. It's not that hard to write one for your own needs. But there is a prebaked package in the npm repository which are worth your attention:
log-process-errors
Its features include:
- Handles all such error conditions -- and if new error conditions are added, this package will surely be updated to handle them as well
- An API with which you can direct information to a logging service
- Customization of what treatment to give to error indications
- Pretty-printing errors making them easier to read and see
- Including stack traces for errors that do not normally print them
It's a relatively easy package to install and use. The only qualm is the number of supporting packages that come along with it, and the resulting footprint in node_modules.
Setting up a Node.js project to use log-process-errors
For this example, let's make a blank project and write a couple simple scripts.
$ npm init -y
This generates a simple package.json with all the defaults.
$ npm install log-process-errors --save
npm notice created a lockfile as package-lock.json. You should commit this file.
npm WARN capture-errors@1.0.0 No description
npm WARN capture-errors@1.0.0 No repository field.
+ log-process-errors@7.0.1
added 34 packages from 64 contributors and audited 34 packages in 9.871s
7 packages are looking for funding
run `npm fund` for details
found 0 vulnerabilities
This installs the the package. Note that it added 34 subsidiary packages.
Simple example - Uncaught exceptions
Let's start with the simplest, an uncaught Exception. In such a circumstance your code is throwing an error, and there is a path through which that Exception makes its way to the event loop. Somewhere along that path your code should have caught the Exception, but it didn't.
Let's try an ultra-simple example. Create a file named ex1.mjs containing:
import logProcessErrors from 'log-process-errors'
logProcessErrors({});
throw new Error('Something bad happened');
An important thing to know is that log-process-errors only exports a ES6 module. Our examples will be written as ES6 modules. To learn about using ES6 modules from a CommonJS modules, see: Loading an ES6 module in a Node.js CommonJS module
With that out of the way, let's examine the code.
The logProcessErrors function sets up the log-process-errors module. It takes an options object with which we can customize the behavior. For now let's leave that with the default.
To generate an uncaught Exception, we just throw one. Running the program we get this:

We have an error, with a useful stack trace, and colors. This looks better than the default error message. To give us a comparison, create another file named ex2.mjs containing just the throw new Exception statement. Running it we get this:
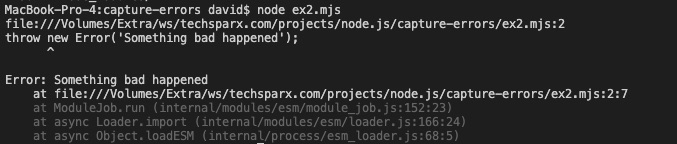
It's largely the same error, though I find myself confused over why it is showing the syntax. But the big issue is, if your application prints a lot of output, which of these messages would you more likely see? Would the default error message be lost in the sea of other notifications? Would the improved colorized error stand out and be seen?
If this was too trivial an example, try another which you can name fs1.mjs:
import fs from 'fs/promises';
import logProcessErrors from 'log-process-errors'
logProcessErrors({});
await fs.unlink('unknown-file.txt');
Node.js now supports top-level use of the await keyword, in ES6 modules: Node.js Script writers: Top-level async/await now available Hence, ES6 modules are preferred for writing simple scripts, because you can freely use await to handle asychronicities.
In any case, the fs.unlink call will throw an Exception so long as that file does not exist.

Very nice. Not clear why there's no stack trace.
Unhandled Promise rejection
The next scenario is about what happens if a Promise is rejected, but nothing catches the rejection. That would be like applying for a job, to be rejected by that company, and then not seeing the rejection notice.
The existence of async/await somewhat obscures when we generate a Promise because they're now handled automatically inside the await keyword. Let's start with an explicit Promise, by creating a file named unhandled.mjs:
import logProcessErrors from 'log-process-errors'
logProcessErrors({});
const promise = Promise.reject(new Error('Something bad happened'));
// promise.catch(() => {});
This explicitly creates a Promise that is in the reject state. A more normal pattern to do this is:
const promise = new Promise((resolve, reject) => {
// .. do something
// .. upon detecting an error:
if (errorCaught) reject(new Error('Something bad hapened'));
});
In any case, let's run the unhandled.mjs example:

And, we get the unhandledRejection error. If we add await Promise.reject then it changes to an uncaughtException error. If we uncomment the promise.catch the error silently disappears.
But, that was artificial, so let's try something a little more real. Suppose you forgot the await keyword in the fs1 example? Create fs2.mjs containing this:
import fs from 'fs/promises';
import logProcessErrors from 'log-process-errors'
logProcessErrors({});
fs.unlink('unknown-file.txt');
Because fs.unlink returns a Promise in this case, we need to handle the Promise to see the status. That's what the await keyword did in the original example. We know this will cause a rejection, so let's see what happens:

With fs1 we get uncaughtException because the await keyword catches the rejected Promise. With fs2 we instead get uncaughtRejection because we forgot to wait for the Promise.
Multiple Promise resolve
This next error is a little harder to grasp, but it boils down to a Promise object where the resolve or reject callbacks were called more than once. The rule is each Promise object is to have resolve or reject invoked at most one time, and it is an error to call either more than once. Specifically, multipleResolves is emitted when:
- Resolved more than once.
- Rejected more than once.
- Rejected after resolve.
- Resolved after reject.
Create a file named multi-resolve.mjs containing:
import logProcessErrors from 'log-process-errors'
logProcessErrors({});
await new Promise((resolve, reject) => {
resolve();
reject(new Error('Something bad happened'));
});
This was artificial, so let's consider how this might happen in real life. A typical error with callback functions wrapped by a Promise is not properly ensuring resolve and/or reject is called only once. Try changing the end of multi-resolve.mjs to this:
import fs from 'fs';
...
/* await new Promise((resolve, reject) => {
resolve();
reject(new Error('Something bad happened'));
}); */
await new Promise((resolve, reject) => {
fs.unlink('does-not-exist.txt', err => {
if (err) reject(err);
resolve();
});
});
In this case we have imported the non-Promises version of the fs package. That means we have a callback function to deal with, and to use it with the await keyword we need to generate a Promise as a wrapper as shown here. So... with the code as written, what happens if there is an error? Isn't both reject and resolve invoked?
Indeed, we get the warning over the Promise being both rejected and resolved. We also get an uncaughtException because this code does not handle the error as discussed above.
Obviously it's better to write that wrapper as:
await new Promise((resolve, reject) => {
fs.unlink('does-not-exist.txt', err => {
if (err) {
reject(err);
} else {
resolve();
}
});
});
But the first is an easy mistake to make. And, in any case, the async/await implementation is a zillion times cleaner, so it's recommended to use that whenever possible.
Uncaught errors in callbacks
The last issue to discuss is not one of the error events emitted by the process object. Instead it is a scenario which happened in my application, and which led me to look into this. I had an error condition silently occurring an event handler, which I didn't know about.
To look at an example, create a file named event-handler.mjs containing:
import EventEmitter from 'events';
import logProcessErrors from 'log-process-errors'
logProcessErrors({});
const emitter = new EventEmitter();
emitter.on('crash', () => {
throw new Error('Something bad happened');
});
emitter.emit('crash');
The EventEmitter class is used in lots of objects in the Node.js platform. For example HTTPServer and HTTPClient are EventEmitter's. The API says to use .on('event-name'...) to listen to the events, then inside the implementation .emit('event-name') triggers the event. But a big failure of the EventEmitter is that the originator of the event does not receive any notification of whether the event handler succeeded or failed or ever completed.
In my application I had to catch the error, and create a mechanism to surface the error in a useful way. But the first step was to even know that the error was happening.
In this case we've created a dummy EventEmitter, and defined a handler for a crash event. Inside the handler we generate an Exception. This mimics the situation of an error happening in your event handler.

And, there we go, the error is caught.
Options object for log-process-errors
This package takes an options object with which to tailor its behavior.
For every example so far we used an empty object. The log-process-errors options object lets us:
- Specify a function to handle logging
- Specify the logging level for each kind of event
- Specify whether to exit on certain kinds of errors
- Specify to fail, for test harness purposes, on certain kinds of errors
- Specify whether to use colors in the output
To try this, duplicate multi-resolve.mjs as options.mjs and make this change:
logProcessErrors({
log: function(error, level, originalError) {
console.error(`ERROR ${level} `, originalError, error);
},
level: { warning: 'warn', multipleResolves: 'info', default: 'error' },
colors: false
});
Leave everything else as-is, because we're interested in trying different options.
The log function we'd use in a real application would send information to a logging service. But, this function lets us inspect the data provided with a loggable event, namely the logging level, the original error, and the generated error.
The level option lets us describe the logging level to use for specific kinds of errors.
The colors option says whether to use colors in the output, or not. You might be logging to a file where colors don't make sense.
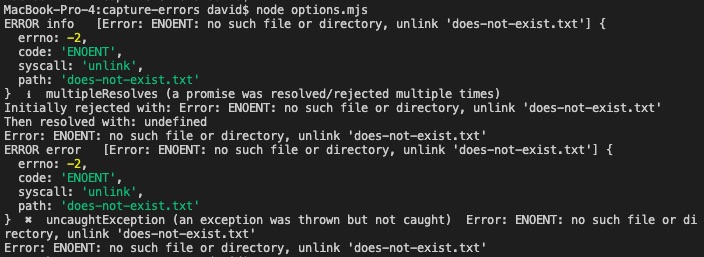
We see that the format of the output has changed, for example we do not have the stack traces. Nor is there the color coding. If you change the settings in the level and colors fields, you can change this around. For example set colors to true, then set multipleResolves to warn, and you see it is color coded as yellow.
Summary
The log-process-errors package helps us improve our applications by automatically notifying us of errors we might have missed otherwise. Errors can happen that weren't surfaced in front of us, letting an unaddressed error fester in our application. This could be like that tree falling in the forest that nobody hears.
For many years nobody heard that the forests were crying out because there isn't the typical rainfall any longer. In California the weakened state of the trees allowed bark beetles to run rampant, killing a hundred million trees. And now, every year California has ever-larger wildfires, causing widespread destruction, and spewing a large amount of toxic smoke over our cities.
This pattern of missing error conditions doesn't just affect our applications, but the physical world we live in.

Books by David Herron




(Sponsored)









